我们将高可用性 (HA) 定义为系统在其中一台或多台服务器发生故障后继续运行的能力。
高可用性的一部分是故障转移,我们将其定义为在服务器发生故障时客户端连接从一台服务器迁移到另一台服务器的能力,以便客户端应用程序可以继续运行。
1. 术语
为了始终如一地讨论配置和运行时行为,我们需要定义一些名词和形容词。这些术语将在整个文档、配置、源代码和运行时日志中使用。
1.1. 配置
这些名词标识了代理的配置方式,例如在 broker.xml 中。配置允许代理配对在一起作为主备(即HA 对的代理)。
- 主
-
这标识了高可用性配置中的主要代理。通常,此代理上的硬件性能将高于备用代理上的硬件。通常,此代理会在备用代理之前启动,并且大部分时间处于活动状态。
每个主服务器可以与一个备用服务器配对。可以配置其他备用服务器,但主服务器将只与一个备用服务器配对。当主服务器出现故障时,备用服务器将接管。此时,如果配置了其他备用服务器,则接管的备用服务器将与其中一个备用服务器配对。
- 备用
-
这标识了在高可用性配置中主代理发生故障时应该接管的代理。通常,此代理上的硬件性能将低于主代理上的硬件。通常,此代理将在主代理之后启动,并且大部分时间处于被动状态。
1.2. 运行时
这些形容词描述了代理在运行时的行为。例如,您可以拥有一个被动的主代理或一个主动的备用代理。
- 主动
-
这标识了高可用性配置中接受远程连接的代理。例如,考虑以下场景:主代理已发生故障,其备用代理已接管。此时,备用代理将被描述为主动,因为它正在接受远程连接。
- 被动
-
这标识了高可用性配置中不接受远程连接的代理。例如,考虑以下场景:主代理已启动,然后备用代理已启动。备用代理将是被动的,因为它没有接受远程连接。它正在等待主代理发生故障,然后再激活并开始接受远程连接。
2. HA 策略
Apache ActiveMQ Artemis 支持两种主要的备份服务器策略
-
共享存储
-
复制
这些策略通过 ha-policy 配置元素进行配置。
|
备份什么?
只有写入存储的消息数据才能在故障转移后幸存。任何未写入存储的消息数据在故障转移后将不可用。 |
|
需要集群
HA 配置的先决条件是需要一个合适的 集群 配置。集群配置允许服务器向其主备(或集群中的任何其他节点)宣布其存在。 |
从技术上讲,还有第三种策略称为 primary-only,它完全省略了备用代理。这用于配置 缩容。如果未提供任何策略,则这是默认策略。
2.1. 共享存储
当使用共享存储时,主服务器和备用服务器使用共享文件系统共享相同的整个数据目录。这包括分页目录、日志目录、大消息和绑定日志。
当主服务器发生故障时,它将释放对共享日志的锁定,并允许备用服务器激活。然后,备用服务器将从共享文件系统加载数据并接受来自客户端的远程连接。
通常,这将是某种高性能存储区域网络 (SAN)。网络附加存储 (NAS),例如 NFS 挂载,是可行的,但不会提供最佳性能。
共享存储配置的主要优点之一是主节点和备用节点之间不会发生任何复制,这意味着在正常操作期间,它不会因复制开销而遭受任何性能损失。
共享存储与复制相比的一个潜在重大缺点是,它需要一个共享文件系统,并且当备用服务器激活时,它需要从共享存储加载日志,这可能需要一些时间,具体取决于存储中的数据量和存储的速度。
如果您在正常操作期间需要最高的性能,那么请获得快速 SAN 的访问权限并处理稍微慢一些的故障转移(取决于数据量)。
|
如何处理脑裂?
共享存储配置天生不受 脑裂 影响。 |
2.1.1. 共享存储配置
主服务器和备用服务器都必须将日志目录的位置配置到相同的共享位置(如 持久性文档 中所述)。
主
主代理需要在 broker.xml 中进行以下基本配置
<ha-policy>
<shared-store>
<primary/>
</shared-store>
</ha-policy>其他参数
- failover-on-shutdown
-
此代理的正常关闭是否会使备用代理激活。
如果为
false,则如果此代理正常关闭(例如,使用 Ctrl-C),备用服务器将保持被动状态。请注意,如果为false并且您希望发生故障转移,则可以使用管理 API,如 此处 所述。如果为
true,则当此服务器停止时,备用服务器将激活。默认值为
false。 - wait-for-activation
-
此设置仅适用于嵌入式用例,其中主代理已发生故障,备用代理已激活,并且主代理已重新启动。默认情况下,当调用
org.apache.activemq.artemis.core.server.ActiveMQServer.start()时,代理将阻塞,直到主代理实际从备用代理接管(即通过故障恢复或通过备用代理实际停止)。将wait-for-activation设置为false会阻止start()阻塞,以便将控制权返回给调用者。调用者可以使用waitForActivation()等待代理激活,或者仅使用getState()检查当前状态。默认值为true。
备用
备用代理需要在 broker.xml 中进行以下基本配置
<ha-policy>
<shared-store>
<backup/>
</shared-store>
</ha-policy>其他参数
- allow-failback
-
此备用代理是否会在其主代理重新启动并请求接管其位置时自动停止。用例是当主服务器停止,其备用服务器接管其职责,稍后主服务器重新启动并请求现在处于活动状态的备用服务器停止,以便主服务器可以再次接管。默认值为
true。 - failover-on-shutdown
-
此代理的正常关闭是否会使备用代理激活。
如果为
false,则如果此代理正常关闭(例如,使用 Ctrl-C),备用服务器将保持被动状态。请注意,如果为false并且您希望发生故障转移,则可以使用管理 API,如 此处 所述。如果为
true,则当此服务器停止时,备用服务器将激活。默认值为
false。这仅适用于此备用代理因其主代理发生故障而激活的情况。 - scale-down
-
如果提供此参数,则此备用代理将在故障转移后缩容,而不是变得活跃。这实际上只适用于共置配置,其中备用代理将在同一个 JVM 中将其消息缩容到主代理。
- restart-backup
-
此备用代理是否会在因故障恢复或缩容而停止后重新启动。默认值为
false。
NFS 挂载建议
如果您选择使用 NFS 实现共享存储配置,以下是一些建议的配置选项。这些设置旨在提高可靠性,并帮助代理快速检测到 NFS 问题并自行关闭,以便客户端可以故障转移到正常工作的代理。
- sync
-
指定将所有更改立即刷新到磁盘。
- intr
-
允许 NFS 请求在服务器关闭或无法访问时被中断。
- noac
-
禁用属性缓存。需要此行为才能在多个客户端之间实现属性缓存一致性。
- soft
-
指定如果 NFS 服务器不可用,应报告错误,而不是等待服务器恢复联机。
- lookupcache=none
-
禁用查找缓存。
- timeo=n
-
NFS 客户端(即代理)在尝试重新请求之前等待 NFS 服务器响应的时间(以十分之一秒为单位)。对于通过 TCP 连接的 NFS,默认
timeo值为600(60 秒)。对于通过 UDP 连接的 NFS,客户端使用自适应算法来估计常用请求类型(例如读取和写入请求)的适当超时值。 - retrans=n
-
NFS 客户端在尝试进一步恢复操作之前重新请求的次数。
|
配置 |
2.2. 复制
当使用复制时,主服务器和备用服务器不共享相同的数据目录。所有数据同步都通过网络完成。因此,主服务器收到的所有(持久)数据都将复制到备用服务器。
请注意,备份服务器在启动时首先需要从主服务器同步所有现有数据,然后才能在主服务器发生故障时替换主服务器。 因此,与使用共享存储不同,备份只有在完成与主服务器的数据同步后才会完全投入运营。 此过程所需的时间取决于要同步的数据量和连接速度。
|
一般来说,同步是与当前网络流量并行发生的,因此不会对当前客户端造成任何阻塞。 然而,在这个过程的最后有一个关键时刻,复制服务器必须完成同步并确保备份确认已完成。 复制服务器和备份之间的这种交换将阻塞任何与日志相关的操作。 此交换阻塞的最长时间由 |
由于复制将在备份处创建数据的副本,因此,如果故障转移成功,则备份的数据将比主服务器的数据更新。 如果您将备份配置为允许回退到主服务器,则当主服务器重新启动时,它将处于被动状态,而活动备份将将其数据与被动主服务器同步,然后停止,以允许被动主服务器再次变为活动状态。 如果两台服务器都关闭,则管理员将必须确定哪台服务器具有最新数据。
|
与共享存储的重要区别
如果共享存储备份未找到主服务器,则它将直接激活并像主服务器一样处理客户端请求。 但是,在复制情况下,备份只是不断等待主服务器进行配对,因为备份不知道其数据是否是最新的。 它不能单方面决定激活。 为了使用当前数据激活复制备份,管理员必须更改其配置,使其通过将 |
2.2.1. 分裂脑
"分裂脑"是一个潜在的问题,了解它很重要。 整章都致力于解释它是什么以及如何在高级别上缓解它。 阅读完它之后,您将了解仲裁投票和可插拔锁管理器配置之间的主要区别,这些区别将在后面的部分中引用。
2.2.2. 复制配置
在共享存储配置中,代理根据其共享存储设备相互配对。 但是,由于复制配置没有这样的共享存储设备,因此它们必须以另一种方式找到彼此。 服务器可以使用primary或backup元素中的相同group-name明确地分组在一起。 备份将只连接到与同一节点组名称共享的服务器。
group-name示例假设您有 5 个主服务器和 6 个备份服务器
加入集群后, 两个 |
如果没有配置group-name,则备份将搜索它可以在集群中找到的任何主服务器。 它尝试与每个主服务器复制,直到找到一个没有配置当前备份的主服务器。 如果没有可用的主服务器,它将等待集群拓扑更改并重复该过程。
主服务器
主代理需要在 broker.xml 中进行以下基本配置
<ha-policy>
<replication>
<primary/>
</replication>
</ha-policy>其他参数
- group-name
-
如果设置,备份服务器将只与具有匹配 group-name 的主服务器配对。 有关更多详细信息,请参阅上面。 对仲裁投票和可插拔锁管理器都有效。
- cluster-name
-
用于复制的
cluster-connection的名称。 此设置仅在您配置多个集群连接时才需要。 如果配置,则使用具有此名称的集群配置的连接器配置,当连接到集群以发现是否已运行活动服务器时,请参阅check-for-active-server。 如果未设置,则使用默认集群连接配置(即配置的第一个)。 对仲裁投票和可插拔锁管理器都有效。 - max-saved-replicated-journals-size
-
此选项指定服务器作为被动备份启动时要保留多少个复制备份目录。 每次服务器作为被动备份启动时,所有以前的数据都会移动到
oldreplica.{id}目录,其中{id}是不断增长的备份索引。 此参数设置磁盘上保留的此类目录的最大数量。 对仲裁投票和可插拔锁管理器都有效。 - check-for-active-server
-
启动时是否使用我们自己的服务器 ID 检查集群是否有活动服务器。 这是一个重要的选项,用于在故障转移发生且主服务器重新启动时避免分裂脑。 默认值为
false。 仅对仲裁投票有效。 - initial-replication-sync-timeout
-
复制服务器在初始复制过程完成时等待备份确认已收到所有必要数据的时长。 默认值为
30000;以毫秒为单位。 对仲裁投票和可插拔锁管理器都有效。在此期间内,任何与日志相关的操作都将被阻塞。 - vote-on-replication-failure
-
如果复制丢失,此主代理是否应该投票以保持活动状态。 默认值为
false。 仅对仲裁投票有效。 - quorum-size
-
复制丢失后投票使用的仲裁大小,-1 表示使用当前集群大小。 默认值为
-1。 仅对仲裁投票有效。 - vote-retries
-
如果我们作为备份启动并失去与主服务器的连接,我们应该尝试投票以获得仲裁多少次,然后再重新启动。 默认值为
12。 仅对仲裁投票有效。 - vote-retry-wait
-
每次投票尝试之间等待的时长(以毫秒为单位)。 默认值为
5000。 仅对仲裁投票有效。 - quorum-vote-wait
-
等待投票结果的时长(以秒为单位)。 默认值为
30。 仅对仲裁投票有效。 - retry-replication-wait
-
如果我们作为备份启动,在尝试重新复制之前等待多长时间(以毫秒为单位),以便在无法找到主服务器后尝试重新复制。 默认值为
2000。 对仲裁投票和可插拔锁管理器都有效。 - manager
-
此元素控制可插拔锁管理器配置,并且是必需的。 它有两个子元素
-
class-name- 实现org.apache.activemq.artemis.lockmanager.DistributedLockManager的类的名称。 默认值为org.apache.activemq.artemis.lockmanager.zookeeper.CuratorDistributedLockManager,它与 ZooKeeper 集成。 -
properties- 一系列property元素,每个元素都有key和value属性,用于配置插件。这是一个简单的示例
<ha-policy> <replication> <primary> <manager> <class-name>org.foo.MyQuorumVotingPlugin</class-name> <properties> <property key="property1" value="value1"/> <property key="property2" value="value2"/> </properties> </manager> </primary> </replication> </ha-policy>
-
- coordination-id
-
这适用于竞争主代理。 仅在使用可插拔锁管理器时才有效。
备份
备用代理需要在 broker.xml 中进行以下基本配置
<ha-policy>
<replication>
<backup/>
</replication>
</ha-policy>其他参数
- group-name
-
如果设置,备份服务器将只与具有匹配 group-name 的主服务器配对。 有关更多详细信息,请参阅上面。 对仲裁投票和可插拔锁管理器都有效。
- cluster-name
-
用于复制的
cluster-connection的名称。 此设置仅在您配置多个集群连接时才需要。 如果配置,则使用具有此名称的集群配置的连接器配置,当连接到集群以发现是否已运行活动服务器时,请参阅check-for-active-server。 如果未设置,则使用默认集群连接配置(即配置的第一个)。 对仲裁投票和可插拔锁管理器都有效。 - max-saved-replicated-journals-size
-
此选项指定服务器作为被动备份启动时要保留多少个复制备份目录。 每次服务器作为被动备份启动时,所有以前的数据都会移动到
oldreplica.{id}目录,其中{id}是不断增长的备份索引。 此参数设置磁盘上保留的此类目录的最大数量。 对仲裁投票和可插拔锁管理器都有效。 - scale-down
-
如果提供此参数,则此备用代理将在故障转移后缩容,而不是变得活跃。这实际上只适用于共置配置,其中备用代理将在同一个 JVM 中将其消息缩容到主代理。
- restart-backup
-
如果备份服务器已停止,由于回退或缩容而停止,它是否会重新启动。 默认值为
false。 - allow-failback
-
当主服务器重新启动并请求接管其位置时,此备份是否会自动停止。 使用场景是,当主服务器停止并且其备份接管其职责时,主服务器随后重新启动,并请求现在处于活动状态的备份停止,以便主服务器可以再次接管。 默认值为
true。 对仲裁投票和可插拔锁管理器都有效。 - initial-replication-sync-timeout
-
故障转移后,当备份已激活时,会在主服务器重新启动并作为备份连接时(例如,用于回退)强制执行此操作。 复制服务器在初始复制过程完成时等待备份确认已收到所有必要数据的时长。 默认值为
30000;以毫秒为单位。 对仲裁投票和可插拔锁管理器都有效。在此期间内,任何与日志相关的操作都将被阻塞。 - vote-on-replication-failure
-
如果复制丢失,此主代理是否应该投票以保持活动状态。 默认值为
false。 仅对仲裁投票有效。 - quorum-size
-
复制丢失后投票使用的仲裁大小,-1 表示使用当前集群大小。 默认值为
-1。 仅对仲裁投票有效。 - vote-retries
-
如果我们作为备份启动并失去与主服务器的连接,我们应该尝试投票以获得仲裁多少次,然后再重新启动。 默认值为
12。 仅对仲裁投票有效。 - vote-retry-wait
-
每次投票尝试之间等待的时长(以毫秒为单位)。 默认值为
5000。 仅对仲裁投票有效。 - quorum-vote-wait
-
等待投票结果的时长(以秒为单位)。 默认值为
30。 仅对仲裁投票有效。 - retry-replication-wait
-
如果我们作为备份启动,在尝试重新复制之前等待多长时间(以毫秒为单位),以便在无法找到主服务器后尝试重新复制。 默认值为
2000。 对仲裁投票和可插拔锁管理器都有效。 - manager
-
此元素控制可插拔锁管理器配置,并且是必需的。 它有两个子元素
-
class-name- 实现org.apache.activemq.artemis.lockmanager.DistributedLockManager的类的名称。 默认值为org.apache.activemq.artemis.lockmanager.zookeeper.CuratorDistributedLockManager,它与 ZooKeeper 集成。 -
properties- 一系列property元素,每个元素都有key和value属性,用于配置插件。这是一个简单的示例
<ha-policy> <replication> <backup> <manager> <class-name>org.foo.MyQuorumVotingPlugin</class-name> <properties> <property key="property1" value="value1"/> <property key="property2" value="value2"/> </properties> </manager> <allow-failback>true</allow-failback> </backup> </replication> </ha-policy>
-
2.2.3. Apache ZooKeeper 集成
默认的可插拔锁管理器实现使用Apache Curator与Apache ZooKeeper集成。
ZooKeeper 插件配置
这是一个基本的配置示例
<ha-policy>
<replication>
<primary>
<manager>
<class-name>org.apache.activemq.artemis.lockmanager.zookeeper.CuratorDistributedLockManager</class-name>
<properties>
<property key="connect-string" value="127.0.0.1:6666,127.0.0.1:6667,127.0.0.1:6668"/>
</properties>
</manager>
</primary>
</replication>
</ha-policy>+ 注意:由于使用了默认值,因此class-name在技术上不是必需的,但为了清晰起见,它已包含在内。
可用属性
connect-string-
(无默认值)
session-ms-
(默认值为 18000 毫秒)
session-percent-
(默认值为 33);应该≤默认值(有关更多信息,请参阅TN14)
connection-ms-
(默认值为 8000 毫秒)
retries-
(默认值为 1)
retries-ms-
(默认值为 1000 毫秒)
namespace-
(无默认值)
提高可靠性
ZooKeeper 集群的配置是用户的责任,但以下是一些提高仲裁服务可靠性的建议
-
根据ZooKeeper 3.6.3 管理员指南,代理
session_ms必须≥ 2 * 服务器心跳时间且≤ 20 * 服务器心跳时间。 这直接影响备份可以多快故障转移到隔离/杀死/无响应的主服务器。 越高,速度越慢。 -
代理机上的 GC 应该允许将 GC 暂停时间保持在
session_ms的 1/3 内,以便让 ZooKeeper 心跳协议可靠地工作。 如果不可能,最好增加session_ms,从而接受更慢的故障转移。 -
ZooKeeper 必须有足够的资源来将 GC(和操作系统)暂停时间保持得远小于服务器心跳时间。 请根据代理的预期负载认真考虑代理和 ZooKeeper 节点是否应该共享相同的物理机。
-
网络隔离保护需要配置≥3 个 ZooKeeper 节点
如前所述,session-ms影响故障转移持续时间。 被动代理可以在session-ms过期后激活,或者如果活动代理自愿放弃其角色(例如,在回退/手动代理停止期间,它会立即发生)。
对于前一种情况(活动代理不再存在的会话过期),被动代理可以使用以下方法检测无响应的活动代理:
-
集群连接 PING(受connection-ttl 调整的影响)
-
已关闭的 TCP 连接通知(取决于 TCP 配置和网络堆栈/拓扑结构)
建议是将connection-ttl调整到足够低的程度,以便尽快尝试故障转移,同时考虑到整个故障转移持续时间不能小于配置的session-ms。
|
备份仍然需要仔细配置 connection-ttl,以便在故障转移之前及时向仲裁管理器发送请求以变为活动状态。 |
2.2.4. 竞争主代理
当将仲裁委派给可插拔实现时,主和备份的角色就不那么重要了。 两个代理可以竞争激活,获胜者激活为主代理,失败者担任备份角色。 重新启动时,任何拥有最新日志的同行服务器都可以激活。 关键是代理需要提前知道它们将协商的标识。 在复制的 primary ha-policy 中,我们可以将 coordination-id 显式设置为集群中所有同行的公共值。
<ha-policy>
<replication>
<primary>
<manager>
<class-name>org.apache.activemq.artemis.lockmanager.zookeeper.CuratorDistributedLockManager</class-name>
<properties>
<property key="connect-string" value="127.0.0.1:6666,127.0.0.1:6667,127.0.0.1:6668"/>
</properties>
</manager>
<coordination-id>peer-journal-001</coordination-id>
</primary>
</replication>
</ha-policy>作为 coordination-id 提供的字符串值将在内部转换为 16 字节的 UUID,因此可能无法立即识别或可读。 但是,它将确保所有“同行”协商。 |
3. 回退到主服务器
主服务器发生故障后,备份服务器接管了其职责,您可能希望重新启动主服务器并让客户端回退。
3.1. 共享存储回退
在共享存储的情况下,您有几种选择
-
只需重新启动主服务器并停止备份服务器。 您可以通过停止进程本身来完成此操作。
-
或者,您可以在备份服务器上将
allow-failback设置为true,这将强制已变为活动状态的备份服务器自动停止。 此配置将如下所示<ha-policy> <shared-store> <backup> <allow-failback>true</allow-failback> </backup> </shared-store> </ha-policy>
在共享存储的情况下,还可以在正常服务器关闭时导致故障转移发生,要启用此功能,请将以下属性在 primary 或 backup 上的 ha-policy 配置中设置为 true,如下所示
<ha-policy>
<shared-store>
<primary>
<failover-on-shutdown>true</failover-on-shutdown>
</primary>
</shared-store>
</ha-policy>默认情况下,此属性设置为 false,如果您碰巧将其设置为 false 但仍然希望正常停止服务器并导致故障转移,则可以使用管理 API,如 管理 中所述。
您还可以强制活动备份在主服务器恢复时关闭,从而允许主服务器自动接管,方法是在 broker.xml 配置文件中设置以下属性,如下所示
<ha-policy>
<shared-store>
<backup>
<allow-failback>true</allow-failback>
</backup>
</shared-store>
</ha-policy>3.2. 复制回退
与共享存储一样,allow-failback 选项可以为仲裁投票和可插拔锁管理器复制配置设置。
3.2.1. 仲裁投票
<ha-policy>
<replication>
<backup>
<allow-failback>true</allow-failback>
</backup>
</replication>
</ha-policy>使用仲裁投票复制,您需要在 primary 配置中设置额外的属性 check-for-active-server 为 true。 如果设置为 true,则在启动期间,主服务器将首先使用其 nodeID 在集群中搜索另一个活动服务器。 如果找到一个,它将与该服务器联系并尝试“回退”。 由于这是一个远程复制场景,因此主服务器必须将其数据与使用其 ID 运行的备份服务器同步。 一旦它们同步,它将请求另一个服务器(它假设它是一个接管其职责的备份服务器)关闭以便它接管。 这是必要的,因为否则主服务器没有办法知道是否发生了故障转移,如果有,接管其职责的服务器是否仍在运行。 要在您的 broker.xml 配置文件中配置此选项,请按如下所示
<ha-policy>
<replication>
<primary>
<check-for-active-server>true</check-for-active-server>
</primary>
</replication>
</ha-policy>|
请注意,如果在发生故障转移后重新启动主服务器,则 |
3.2.2. 可插拔锁管理器
使用仲裁投票复制和使用锁管理器复制之间的一个关键区别是,使用仲裁投票,如果主服务器无法联系到其 nodeID 的任何活动服务器,则它会单方面激活。 使用可插拔锁管理器,协调职责被委托给第三方。 没有单方面决定。 主服务器只有在知道它拥有其 nodeID 识别的最新日志版本时才会激活。
简而言之:**使用可插拔锁管理器时,主服务器无法在未经许可的情况下激活**。
以下是一个示例配置
<ha-policy>
<replication>
<manager>
<!-- some meaningful configuration -->
</manager>
<primary>
<!-- no need to check-for-active-server anymore -->
</primary>
</replication>
</ha-policy>3.3. 所有共享存储配置
3.3.1. 主服务器
以下是 HA 策略共享存储的 primary 的所有 ha-policy 配置元素
- failover-on-shutdown
-
此代理的正常关闭是否会使备用代理激活。
如果为
false,则如果此代理正常关闭(例如,使用 Ctrl-C),备用服务器将保持被动状态。请注意,如果为false并且您希望发生故障转移,则可以使用管理 API,如 此处 所述。如果为
true,则当此服务器停止时,备用服务器将激活。默认值为
false。 - wait-for-activation
-
如果设置为 true,则服务器启动将等待它被激活。 如果设置为 false,则服务器启动将在后台完成。 默认值为
true。
3.3.2. 备份服务器
以下是 HA 策略共享存储的 backup 的所有 ha-policy 配置元素
- failover-on-shutdown
-
此代理的正常关闭是否会使备用代理激活。
如果为
false,则如果此代理正常关闭(例如,使用 Ctrl-C),备用服务器将保持被动状态。请注意,如果为false并且您希望发生故障转移,则可以使用管理 API,如 此处 所述。如果为
true,则当此服务器停止时,备用服务器将激活。默认值为
false。 - allow-failback
-
服务器在另一个服务器发出请求接管其位置时是否会自动停止。 使用情况是在备份服务器发生故障转移时。
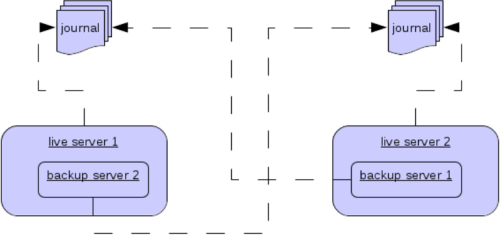
3.3.3. 共置备份服务器
在运行独立服务器时,还可以在与另一个主服务器相同的 JVM 中共置备份服务器。 主服务器可以配置为请求集群中的另一个主服务器在相同的 JVM 中启动备份服务器,无论是使用共享存储还是复制。 新的备份服务器将从创建它的主服务器继承其配置,除了它的名称,它的名称将设置为 colocated_backup_n,其中 n 是服务器创建的备份数量,以及本章后面将讨论的任何目录及其连接器和接收器。 主服务器还可以配置为允许来自备份服务器的请求,以及主服务器可以启动多少个备份服务器。 这样,您可以将备份服务器均匀地分布在整个集群中。 这是通过 broker.xml 文件中的 ha-policy 元素进行配置的,如下所示
<ha-policy>
<replication>
<colocated>
<request-backup>true</request-backup>
<max-backups>1</max-backups>
<backup-request-retries>-1</backup-request-retries>
<backup-request-retry-interval>5000</backup-request-retry-interval>
<primary/>
<backup/>
</colocated>
</replication>
</ha-policy>上面的示例配置为使用复制,在这种情况下,primary 和 backup 配置必须与上一章中正常复制的配置匹配。 shared-store 也受支持
3.4. 配置连接器和接收器
如果 HA 策略为 colocated,则 connectors 和 acceptors 将从创建它的主服务器继承,并根据 backup-port-offset 配置元素的设置进行偏移。 如果将其设置为 100(默认值),并且连接器使用端口 61616,则这将为第一个创建的服务器设置为 61716,为第二个服务器设置为 61816,依此类推。
|
对于 INVM 连接器和接收器,id 将附加 |
3.5. 远程连接器
一些配置的连接器可能用于外部服务器,因此应将其从偏移量中排除。 例如,由集群连接器使用的连接器来为复制的备份服务器执行仲裁投票,可以通过将它们添加到 ha-policy 配置中来省略它们,如下所示
<ha-policy>
<replication>
<colocated>
...
<excludes>
<connector-ref>remote-connector</connector-ref>
</excludes>
...
</colocated>
</replication
</ha-policy>3.6. 配置目录
日志、大型消息和分页的目录将根据 HA 策略进行设置。 如果是共享存储,请求服务器将通知目标服务器使用哪些目录。 如果配置了复制,则目录将从创建服务器继承,但将附加新的备份服务器名称。
下表列出了共置策略的所有 ha-policy 配置元素
- request-backup
-
如果为 true,则服务器将在另一个节点上请求备份
- backup-request-retries
-
主服务器尝试请求备份的次数,
-1表示永远。 - backup-request-retry-interval
-
尝试请求备份服务器之间的重试等待时间。
- max-backups
-
主服务器可以创建的备份数量
- backup-port-offset
-
创建新的备份服务器时要使用的连接器和接收器的偏移量。
4. 缩容
使用主/备份组的另一种方法是配置缩容。 当配置为缩容时,服务器可以将其所有消息和事务状态复制到另一个活动服务器。 这样做的好处是,您不需要完整的备份来提供某种形式的 HA,但这种方法也有缺点,第一个缺点是它只处理服务器停止,而不处理服务器崩溃。 这里的注意事项是,如果您将备份配置为缩容。
另一个缺点是,可能会丢失消息顺序。 这种情况发生在以下场景中,假设您有两个活动服务器,来自单个生产者的消息均匀地分布在两个服务器之间,如果其中一个服务器缩容,则发送回另一个服务器的消息将在队列中的消息之后,因此服务器 1 可能会包含消息 1、3、5、7、9,而服务器 2 可能会包含消息 2、4、6、8、10,如果服务器 2 缩容,则服务器 1 中的顺序将为 1、3、5、7、9、2、4、6、8、10。
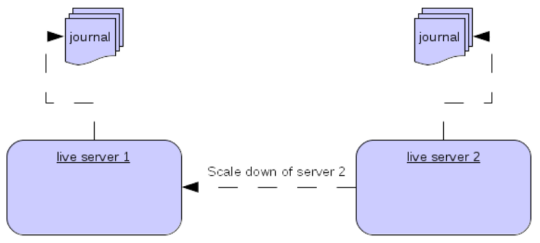
活动服务器缩容的配置如下所示
<ha-policy>
<primary-only>
<scale-down>
<connectors>
<connector-ref>server1-connector</connector-ref>
</connectors>
</scale-down>
</primary-only>
</ha-policy>在这种情况下,服务器配置为使用特定连接器进行缩容,如果未指定连接器,则选择第一个 INVM 连接器,这是为了便于从备份服务器进行缩容的配置。 也可以使用发现进行缩容,这将如下所示
<ha-policy>
<primary-only>
<scale-down>
<discovery-group-ref discovery-group-name="my-discovery-group"/>
</scale-down>
</primary-only>
</ha-policy>4.1. 使用组进行缩容
还可以配置服务器,使其仅缩容到属于同一组的服务器。 这是通过如下所示配置组来完成的
<ha-policy>
<primary-only>
<scale-down>
...
<group-name>my-group</group-name>
</scale-down>
</primary-only>
</ha-policy>在这种情况下,只有属于 my-group 组的服务器才会被缩容。
4.2. 缩容和备份
还可以将缩容与通过备份服务器实现的 HA 混合使用。 如果备份配置为缩容,则在发生故障转移后,备份服务器不会完全启动,而是会立即缩容到另一个活动服务器。 为此最合适的配置是使用 colocated 方法。 这意味着当您启动主服务器时,它们会自动备份,并且当它们关闭时,它们的消息会变得可用于另一个活动服务器。 典型的配置如下所示
<ha-policy>
<replication>
<colocated>
<backup-request-retries>44</backup-request-retries>
<backup-request-retry-interval>33</backup-request-retry-interval>
<max-backups>3</max-backups>
<request-backup>false</request-backup>
<backup-port-offset>33</backup-port-offset>
<primary>
<group-name>purple</group-name>
<check-for-active-server>true</check-for-active-server>
<cluster-name>abcdefg</cluster-name>
</primary>
<backup>
<group-name>tiddles</group-name>
<max-saved-replicated-journals-size>22</max-saved-replicated-journals-size>
<cluster-name>33rrrrr</cluster-name>
<restart-backup>false</restart-backup>
<scale-down>
<!--a grouping of servers that can be scaled down to-->
<group-name>boo!</group-name>
<!--either a discovery group-->
<discovery-group-ref discovery-group-name="wahey"/>
</scale-down>
</backup>
</colocated>
</replication>
</ha-policy>4.3. 缩容和客户端
当服务器停止并准备缩容时,它会向所有客户端发送一条消息,告知它们它缩容到的服务器,然后断开与它们的连接。 在此阶段,客户端将重新连接,但是只有在服务器完成缩容过程后才能成功。 这样做是为了确保客户端重新连接时,任何状态(如队列或事务)都存在。 客户端重新连接时,将应用正常的重新连接设置,因此这些设置应足够高以处理缩容所需的时间。
5. 客户端故障转移
Apache ActiveMQ Artemis 客户端可以配置为接收所有主服务器和备份服务器的信息,以便在连接失败的情况下,客户端可以检测到此问题并重新连接到备份服务器。备份服务器将自动重新创建之前在每个连接上存在的任何会话和消费者,从而使用户无需手动编写手动重新连接逻辑。有关更多详细信息,请参见客户端故障转移
5.1. 处理故障转移期间的阻塞调用
如果客户端代码正在执行对服务器的阻塞调用,等待响应以继续执行,当发生故障转移时,新会话将不会知道正在进行的调用。否则,此调用可能会永远挂起,等待永远不会到来的响应。
为了防止这种情况,Apache ActiveMQ Artemis 将通过使它们抛出javax.jms.JMSException(如果使用 JMS)或错误代码为ActiveMQException.UNBLOCKED的ActiveMQException来解除阻止在故障转移时正在进行的任何阻塞调用。客户端代码需要捕获此异常,如果需要,则重试任何操作。
如果要解除阻止的方法是调用commit()或prepare(),则事务将自动回滚,Apache ActiveMQ Artemis 将抛出javax.jms.TransactionRolledBackException(如果使用 JMS)或错误代码为ActiveMQException.TRANSACTION_ROLLED_BACK的ActiveMQException(如果使用核心 API)。
5.2. 处理使用事务的故障转移
如果会话是事务性的,并且已在当前事务中发送或确认消息,则服务器无法确定在故障转移期间是否已丢失发送的消息或确认。
因此,事务将被标记为仅回滚,并且任何后续尝试提交它都将抛出javax.jms.TransactionRolledBackException(如果使用 JMS)或错误代码为ActiveMQException.TRANSACTION_ROLLED_BACK的ActiveMQException(如果使用核心 API)。
|
此规则的例外情况是通过 JMS 或通过核心 API 使用 XA 时。如果使用两阶段提交,并且已经调用了 prepare,那么回滚可能会导致 |
用户需要捕获异常,并在必要时执行任何客户端方面的本地回滚代码。无需手动回滚会话 - 它已经回滚。用户然后可以在同一会话上重新尝试事务操作。
Apache ActiveMQ Artemis 附带一个功能齐全的示例,演示如何执行此操作,请参见示例章节。
如果在执行 commit 调用时发生故障转移,服务器将如前所述解除对该调用的阻止,以防止挂起,因为不会返回任何响应。在这种情况下,客户端很难确定事务提交是否在发生故障之前实际处理过。
|
如果通过 JMS 或通过核心 API 使用 XA,那么会抛出 |
为了解决此问题,客户端可以简单地在事务中启用重复检测(重复消息检测),并在解除对该调用的阻止后重新尝试事务操作。如果事务在发生故障转移之前确实已成功提交,那么当重新尝试事务时,重复检测将确保在事务中重新发送的任何持久性消息都会在服务器上被忽略,以防止它们被发送超过一次。
|
通过捕获回滚异常并重试,捕获解除阻止的调用并启用重复检测,可以在发生故障的情况下为消息提供一次且仅一次传递保证,从而保证消息 100% 不丢失或重复。 |
5.2.1. 处理使用非事务会话的故障转移
如果会话是非事务性的,则在发生故障转移的情况下,可能会丢失消息或确认。
如果您希望为非事务会话提供一次且仅一次传递保证,请启用重复检测,并捕获如处理故障转移期间的阻塞调用中所述的解除阻止异常
5.2.2. 使用客户端连接器进行故障转移
Apache ActiveMQ Artemis 客户端从集群代理发送的拓扑更新中检索备份连接器。如果客户端的连接选项与集群代理的选项不匹配,则客户端可以定义一个客户端连接器,该连接器将用于代替拓扑中的连接器。要定义客户端连接器,它必须具有与代理中定义的连接器名称匹配的名称,例如假设有一个主代理,其集群连接器名称为node-0,而备份代理的cluster-connector名称为node-1,那么客户端连接 URL 必须定义两个名称为node-0和node-1的连接器
主代理配置
<connectors>
<!-- Connector used to be announced through cluster connections and notifications -->
<connector name="node-0">tcp://:61616</connector>
</connectors>
...
<cluster-connections>
<cluster-connection name="my-cluster">
<connector-ref>node-0</connector-ref>
...
</cluster-connection>
</cluster-connections>备份代理配置
<connectors>
<!-- Connector used to be announced through cluster connections and notifications -->
<connector name="node-1">tcp://:61617</connector>
</connectors>
<cluster-connections>
<cluster-connection name="my-cluster">
<connector-ref>node-1</connector-ref>
...
</cluster-connection>
</cluster-connections>客户端连接 URL
(tcp://:61616?name=node-0,tcp://:61617?name=node-1)?ha=true&reconnectAttempts=-1
5.3. 获取连接失败的通知
JMS 提供了一种标准机制,用于异步获取连接失败的通知:java.jms.ExceptionListener。有关如何使用此机制的更多信息,请咨询 JMS javadoc 或任何好的 JMS 教程。
Apache ActiveMQ Artemis 核心 API 还以org.apache.activemq.artemis.core.client.SessionFailureListener类的形式提供了类似的功能
无论连接是否成功故障转移、重新连接或重新附加,ActiveMQ Artemis 始终会在连接失败的情况下调用任何 ExceptionListener 或 SessionFailureListener 实例,但您可以通过SessionfailureListener上的connectionFailed上传递的failedOver标志,或者通过检查javax.jms.JMSException上的错误代码(它将是以下之一)来确定是否已发生重新连接或重新附加
JMSException 错误代码
- FAILOVER
-
已发生故障转移,我们已成功重新附加或重新连接。
- DISCONNECT
-
未发生故障转移,我们已断开连接。
5.4. 应用程序级故障转移
在某些情况下,您可能不希望自动客户端故障转移,而希望自己处理任何连接故障,并在自己的故障处理程序中编写自己的手动重新连接逻辑。我们将此定义为应用程序级故障转移,因为故障转移是在用户应用程序级别处理的。
要实现应用程序级故障转移,如果您使用的是 JMS,则需要在 JMS 连接上设置ExceptionListener类。如果检测到连接故障,Apache ActiveMQ Artemis 将调用ExceptionListener。在您的ExceptionListener中,您将关闭旧的 JMS 连接,可能会从 JNDI 中查找新的连接工厂实例,并创建新的连接。
有关应用程序级故障转移的工作示例,请参见应用程序层故障转移示例.
如果您使用的是核心 API,那么过程非常类似:您将在核心ClientSession实例上设置FailureListener。